LLMCache.com
Semantic cache for LLM prompts using Chains
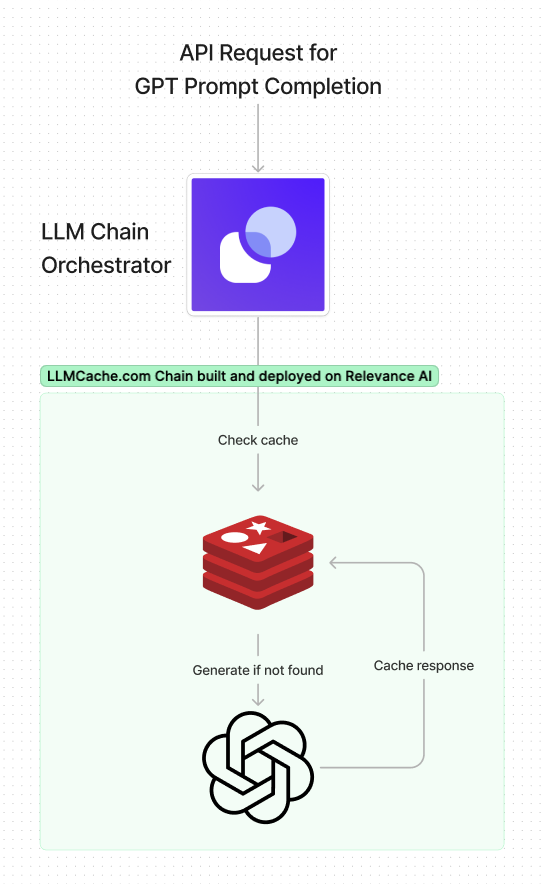
Caching LLM prompts is a great way to reduce expenses. It works by using vector search to identify similar prompts and then returning its response. If there are no similar responses, the request is passed onto the LLM provider to generate the completion.
- Visit chain.relevanceai.com/templates
- Select the LLMCache.com template
- Clone the AI chain in Relevance AI
- Create a Redis database (you can do so via Redis Cloud or Redis Stack)
- Set eviction strategy to always-lfu and create an index with
FT.CREATE llmcache ON JSON PREFIX 1 "llm:" SCHEMA $.prompt_vector_ as prompt_vector_ VECTOR HNSW 6 TYPE FLOAT64 DIM 1536 DISTANCE_METRIC COSINE - Add redis connection string to API key in Project Settings with key "redis-external"
- Use the deployed API for future prompt requests
If you need help with any of these steps, you can reach out to the Relevance AI support team via live chat.
- Daniel, Founder @ Relevance AI